 |
| ||||||||
사용자 인터페이스 및 카탈로그에서 외래 문자가 특수 문자로 잘못 표시되는 이유는 무엇입니까? 예를 들어 "wählen"은 "w%hlen"으로 표시될 수 있습니다.
데이터를 Ariba에 로드할 때 사용되는 문자 세트로 인해 발생합니다. 유니코드 변환 형식-8(UTF-8) 문자 인코딩, 일반적인 문자 집합은 매우 자주 사용되며 이러한 특수 문자는 사용할 수 없습니다. 인코딩을 이러한 특수 문자(예: 서유럽의 경우 ISO-8859-1)를 허용하는 것으로 변경합니다.
이로 인해 Ariba에서 데이터를 내보내서 문제가 발생하는지 확인할 수 있습니다. 내보낸 파일에는 데이터를 Ariba로 가져올 때 사용되는 문자 인코딩이 포함되어 있으며 외래 문자가 모두 제거되었음을 알 수 있습니다.

이 개념은 Ariba에 로드된 카탈로그에도 적용할 수 있습니다. 카탈로그에 외래 문자가 포함되어야 하는 경우 필요한 문자가 포함된 다른 문자 세트로 카탈로그를 인코딩해야 합니다. Ariba에 로드된 각 카탈로그에는 헤더에 "CHARSET" 필드 세트가 있으며, 이는 필요한 문자 세트를 정의하는 데 사용됩니다(CSV 가져오기에 대한 위 정보에 언급된 인코딩 헤더와 유사). 아래 선박은 폴란드 문자를 허용하기 위해 발트어 문자 CHARSET(ISO-8859-13)을 참조하는 카탈로그 헤더의 예를 보여줍니다.
CIF_I_V3.0
LOADMODE: F
SUPPLIERID_DOMAIN: buyersystemid
주석: 2013년 10월 10일 00:00:00 PDT에 생성됨
UNUOM: TRUE
통화: EUR
CHARSET: ISO-8859-13
아래 스크린샷은 폴란드 문자를 사용하여 Ariba에 로드된 항목을 보여 줍니다. 이 항목은 UTF-8로 잘못 인코딩된 후(빨간색으로 강조 표시됨) ISO-8859-13에 올바르게 인코딩되면 두 번 로드되었습니다(녹색으로 강조 표시됨).
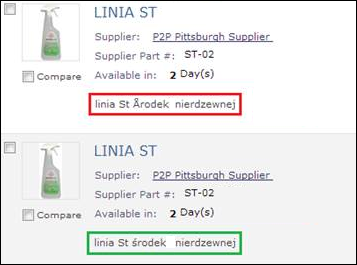
참고: 이것은 Ariba 및 카탈로그에 로드된 마스터 데이터용입니다. 이 정보는 Ariba Spend Visibility 데이터에 적용되지 않을 수 있습니다.
구매